
深度强化学习成名作——DQN
前言:其实很早之前就想开始写写深度强化学习(Deep reinforcement learning)了,但是一年前DQN没调出来,没好意思写哈哈,最近呢无意中把打砖块游戏Breakout训练到平均分接近40分,最高分随便上50(虽说也不算太好,但好歹也体现了DRL的优势),于是就写写吧~
提到深度强化学习的成名作,很多人可能会觉得是2016年轰动一时的AlphaGo,从大众来看是这样的,但真正让深度强化学习火起来并获得学术界蹭蹭往上涨关注度的,当属Deep Q-learning Network(DQN),最早见于2013年的论文《Playing Atari with Deep Reinforcement Learning》。
2012年,深度学习刚在ImageNet比赛大获全胜,紧接着DeepMind团队就想到把深度网络与强化学习结合起来,思想是基于强化学习领域很早就出现的值函数逼近(function approximation),但是通过深度神经网络这一神奇的工具,巧妙地解决了状态维数爆炸的问题!
怎么解决的呢?让我们走进DQN,一探究竟。
CNN实现Q(s, a)
如果我们以纯数学的角度来看动作值函数 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjcuMDAyZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMzAxNC43IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MSIgZD0iTTM5OSAtODBRMzk5IC00NyA0MDAgLTMwVDQwMiAtMTFWLTdMMzg3IC0xMVEzNDEgLTIyIDMwMyAtMjJRMjA4IC0yMiAxMzggMzVUNTEgMjAxUTUwIDIwOSA1MCAyNDRRNTAgMzQ2IDk4IDQzOFQyMjcgNjAxUTM1MSA3MDQgNDc2IDcwNFE1MTQgNzA0IDUyNCA3MDNRNjIxIDY4OSA2ODAgNjE3VDc0MCA0MzVRNzQwIDI1NSA1OTIgMTA3UTUyOSA0NyA0NjEgMTZMNDQ0IDhWM1E0NDQgMiA0NDkgLTI0VDQ3MCAtNjZUNTE2IC04MlE1NTEgLTgyIDU4MyAtNjBUNjI1IC0zUTYzMSAxMSA2MzggMTFRNjQ3IDExIDY0OSAyUTY0OSAtNiA2MzkgLTM0VDYxMSAtMTAwVDU1NyAtMTY1VDQ4MSAtMTk0UTM5OSAtMTk0IDM5OSAtODdWLTgwWk02MzYgNDY4UTYzNiA1MjMgNjIxIDU2NFQ1ODAgNjI1VDUzMCA2NTVUNDc3IDY2NVE0MjkgNjY1IDM3OSA2NDBRMjc3IDU5MSAyMTUgNDY0VDE1MyAyMTZRMTUzIDExMCAyMDcgNTlRMjMxIDM4IDIzNiAzOFY0NlEyMzYgODYgMjY5IDEyMFQzNDcgMTU1UTM3MiAxNTUgMzkwIDE0NFQ0MTcgMTE0VDQyOSA4MlQ0MzUgNTVMNDQ4IDY0UTUxMiAxMDggNTU3IDE4NVQ2MTkgMzM0VDYzNiA0NjhaTTMxNCAxOFEzNjIgMTggNDA0IDM5TDQwMyA0OVEzOTkgMTA0IDM2NiAxMTVRMzU0IDExNyAzNDcgMTE3UTM0NCAxMTcgMzQxIDExN1QzMzcgMTE4UTMxNyAxMTggMjk2IDk4VDI3NCA1MlEyNzQgMTggMzE0IDE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTYxIiBkPSJNMzMgMTU3UTMzIDI1OCAxMDkgMzQ5VDI4MCA0NDFRMzMxIDQ0MSAzNzAgMzkyUTM4NiA0MjIgNDE2IDQyMlE0MjkgNDIyIDQzOSA0MTRUNDQ5IDM5NFE0NDkgMzgxIDQxMiAyMzRUMzc0IDY4UTM3NCA0MyAzODEgMzVUNDAyIDI2UTQxMSAyNyA0MjIgMzVRNDQzIDU1IDQ2MyAxMzFRNDY5IDE1MSA0NzMgMTUyUTQ3NSAxNTMgNDgzIDE1M0g0ODdRNTA2IDE1MyA1MDYgMTQ0UTUwNiAxMzggNTAxIDExN1Q0ODEgNjNUNDQ5IDEzUTQzNiAwIDQxNyAtOFE0MDkgLTEwIDM5MyAtMTBRMzU5IC0xMCAzMzYgNVQzMDYgMzZMMzAwIDUxUTI5OSA1MiAyOTYgNTBRMjk0IDQ4IDI5MiA0NlEyMzMgLTEwIDE3MiAtMTBRMTE3IC0xMCA3NSAzMFQzMyAxNTdaTTM1MSAzMjhRMzUxIDMzNCAzNDYgMzUwVDMyMyAzODVUMjc3IDQwNVEyNDIgNDA1IDIxMCAzNzRUMTYwIDI5M1ExMzEgMjE0IDExOSAxMjlRMTE5IDEyNiAxMTkgMTE4VDExOCAxMDZRMTE4IDYxIDEzNiA0NFQxNzkgMjZRMjE3IDI2IDI1NCA1OVQyOTggMTEwUTMwMCAxMTQgMzI1IDIxN1QzNTEgMzI4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSI3OTEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTE4MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjE2NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iMjA5NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI2MjUiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,不过就是建立一个从状态空间
,不过就是建立一个从状态空间![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMDlleCIgaGVpZ2h0PSIxLjY3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC01NzYuMSA0NjkuNSA3MjEuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 到动作空间
到动作空间 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMjNleCIgaGVpZ2h0PSIxLjY3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC01NzYuMSA1MjkuNSA3MjEuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 的映射,而映射的具体形式是什么,完全可以自己定,只要能够接近真实的最优
的映射,而映射的具体形式是什么,完全可以自己定,只要能够接近真实的最优
就是胜利。于是用CNN完成这种映射的做法应运而生,先上一幅架构图:
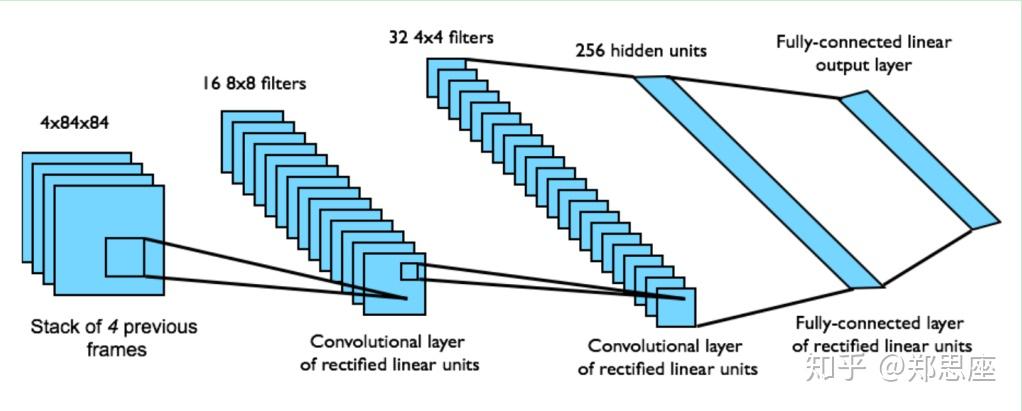
DQN
通过gym模块输出Atari环境的游戏,状态空间都是(210, 160, 3),即210*160的图片大小,3个通道,在输入CNN之前需要通过图像处理二值化并缩小成84*84。由于如果将一张图片作为状态输入信息,很多隐藏信息就会忽略(比如球往哪边飞),于是论文中把连续的4帧图片作为状态输入。所以在pytorch中,CNN的输入就是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIxLjM3NmV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDkyMDMuNSAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQyIiBkPSJNMjMxIDYzN1EyMDQgNjM3IDE5OSA2MzhUMTk0IDY0OVExOTQgNjc2IDIwNSA2ODJRMjA2IDY4MyAzMzUgNjgzUTU5NCA2ODMgNjA4IDY4MVE2NzEgNjcxIDcxMyA2MzZUNzU2IDU0NFE3NTYgNDgwIDY5OCA0MjlUNTY1IDM2MEw1NTUgMzU3UTYxOSAzNDggNjYwIDMxMVQ3MDIgMjE5UTcwMiAxNDYgNjMwIDc4VDQ1MyAxUTQ0NiAwIDI0MiAwUTQyIDAgMzkgMlEzNSA1IDM1IDEwUTM1IDE3IDM3IDI0UTQyIDQzIDQ3IDQ1UTUxIDQ2IDYyIDQ2SDY4UTk1IDQ2IDEyOCA0OVExNDIgNTIgMTQ3IDYxUTE1MCA2NSAyMTkgMzM5VDI4OCA2MjhRMjg4IDYzNSAyMzEgNjM3Wk02NDkgNTQ0UTY0OSA1NzQgNjM0IDYwMFQ1ODUgNjM0UTU3OCA2MzYgNDkzIDYzN1E0NzMgNjM3IDQ1MSA2MzdUNDE2IDYzNkg0MDNRMzg4IDYzNSAzODQgNjI2UTM4MiA2MjIgMzUyIDUwNlEzNTIgNTAzIDM1MSA1MDBMMzIwIDM3NEg0MDFRNDgyIDM3NCA0OTQgMzc2UTU1NCAzODYgNjAxIDQzNFQ2NDkgNTQ0Wk01OTUgMjI5UTU5NSAyNzMgNTcyIDMwMlQ1MTIgMzM2UTUwNiAzMzcgNDI5IDMzN1EzMTEgMzM3IDMxMCAzMzZRMzEwIDMzNCAyOTMgMjYzVDI1OCAxMjJMMjQwIDUyUTI0MCA0OCAyNTIgNDhUMzMzIDQ2UTQyMiA0NiA0MjkgNDdRNDkxIDU0IDU0MyAxMDVUNTk1IDIyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MyIgZD0iTTM0IDE1OVEzNCAyNjggMTIwIDM1NVQzMDYgNDQyUTM2MiA0NDIgMzk0IDQxOFQ0MjcgMzU1UTQyNyAzMjYgNDA4IDMwNlQzNjAgMjg1UTM0MSAyODUgMzMwIDI5NVQzMTkgMzI1VDMzMCAzNTlUMzUyIDM4MFQzNjYgMzg2SDM2N1EzNjcgMzg4IDM2MSAzOTJUMzQwIDQwMFQzMDYgNDA0UTI3NiA0MDQgMjQ5IDM5MFEyMjggMzgxIDIwNiAzNTlRMTYyIDMxNSAxNDIgMjM1VDEyMSAxMTlRMTIxIDczIDE0NyA1MFExNjkgMjYgMjA1IDI2SDIwOVEzMjEgMjYgMzk0IDExMVE0MDMgMTIxIDQwNiAxMjFRNDEwIDEyMSA0MTkgMTEyVDQyOSA5OFQ0MjAgODNUMzkxIDU1VDM0NiAyNVQyODIgMFQyMDIgLTExUTEyNyAtMTEgODEgMzdUMzQgMTU5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY4IiBkPSJNMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODVRMjk0IDY3NCAyNTggNTM0UTIyMCAzODYgMjIwIDM4M1EyMjAgMzgxIDIyNyAzODhRMjg4IDQ0MiAzNTcgNDQyUTQxMSA0NDIgNDQ0IDQxNVQ0NzggMzM2UTQ3OCAyODUgNDQwIDE3OFQ0MDIgNTBRNDAzIDM2IDQwNyAzMVQ0MjIgMjZRNDUwIDI2IDQ3NCA1NlQ1MTMgMTM4UTUxNiAxNDkgNTE5IDE1MVQ1MzUgMTUzUTU1NSAxNTMgNTU1IDE0NVE1NTUgMTQ0IDU1MSAxMzBRNTM1IDcxIDUwMCAzM1E0NjYgLTEwIDQxOSAtMTBINDE0UTM2NyAtMTAgMzQ2IDE3VDMyNSA3NFEzMjUgOTAgMzYxIDE5MlQzOTggMzQ1UTM5OCA0MDQgMzU0IDQwNEgzNDlRMjY2IDQwNCAyMDUgMzA2TDE5OCAyOTNMMTY0IDE1OFExMzIgMjggMTI3IDE2UTExNCAtMTEgODMgLTExUTY5IC0xMSA1OSAtMlQ0OCAxNlE0OCAzMCAxMjEgMzIwTDE5NSA2MTZRMTk1IDYyOSAxODggNjMyVDE0OSA2MzdIMTI4UTEyMiA2NDMgMTIyIDY0NVQxMjQgNjY0UTEyOSA2ODMgMTM3IDY4M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MyIgZD0iTTMwOCAyNFEzNjcgMjQgNDE2IDc2VDQ2NiAxOTdRNDY2IDI2MCA0MTQgMjg0UTMwOCAzMTEgMjc4IDMyMVQyMzYgMzQxUTE3NiAzODMgMTc2IDQ2MlExNzYgNTIzIDIwOCA1NzNUMjczIDY0OFEzMDIgNjczIDM0MyA2ODhUNDA3IDcwNEg0MThINDI1UTUyMSA3MDQgNTY0IDY0MFE1NjUgNjQwIDU3NyA2NTNUNjAzIDY4MlQ2MjMgNzA0UTYyNCA3MDQgNjI3IDcwNFQ2MzIgNzA1UTY0NSA3MDUgNjQ1IDY5OFQ2MTcgNTc3VDU4NSA0NTlUNTY5IDQ1NlE1NDkgNDU2IDU0OSA0NjVRNTQ5IDQ3MSA1NTAgNDc1UTU1MCA0NzggNTUxIDQ5NFQ1NTMgNTIwUTU1MyA1NTQgNTQ0IDU3OVQ1MjYgNjE2VDUwMSA2NDFRNDY1IDY2MiA0MTkgNjYyUTM2MiA2NjIgMzEzIDYxNlQyNjMgNTEwUTI2MyA0ODAgMjc4IDQ1OFQzMTkgNDI3UTMyMyA0MjUgMzg5IDQwOFQ0NTYgMzkwUTQ5MCAzNzkgNTIyIDM0MlQ1NTQgMjQyUTU1NCAyMTYgNTQ2IDE4NlE1NDEgMTY0IDUyOCAxMzdUNDkyIDc4VDQyNiAxOFQzMzIgLTIwUTMyMCAtMjIgMjk4IC0yMlExOTkgLTIyIDE0NCAzM0wxMzQgNDRMMTA2IDEzUTgzIC0xNCA3OCAtMThUNjUgLTIyUTUyIC0yMiA1MiAtMTRRNTIgLTExIDExMCAyMjFRMTEyIDIyNyAxMzAgMjI3SDE0M1ExNDkgMjIxIDE0OSAyMTZRMTQ5IDIxNCAxNDggMjA3VDE0NCAxODZUMTQyIDE1M1ExNDQgMTE0IDE2MCA4N1QyMDMgNDdUMjU1IDI5VDMwOCAyNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTdBIiBkPSJNMzQ3IDMzOFEzMzcgMzM4IDI5NCAzNDlUMjMxIDM2MFEyMTEgMzYwIDE5NyAzNTZUMTc0IDM0NlQxNjIgMzM1VDE1NSAzMjRMMTUzIDMyMFExNTAgMzE3IDEzOCAzMTdRMTE3IDMxNyAxMTcgMzI1UTExNyAzMzAgMTIwIDMzOVExMzMgMzc4IDE2MyA0MDZUMjI5IDQ0MFEyNDEgNDQyIDI0NiA0NDJRMjcxIDQ0MiAyOTEgNDI1VDMyOSAzOTJUMzY3IDM3NVEzODkgMzc1IDQxMSA0MDhUNDM0IDQ0MVE0MzUgNDQyIDQ0OSA0NDJINDYyUTQ2OCA0MzYgNDY4IDQzNFE0NjggNDMwIDQ2MyA0MjBUNDQ5IDM5OVQ0MzIgMzc3VDQxOCAzNThMNDExIDM0OVEzNjggMjk4IDI3NSAyMTRUMTYwIDEwNkwxNDggOTRMMTYzIDkzUTE4NSA5MyAyMjcgODJUMjkwIDcxUTMyOCA3MSAzNjAgOTBUNDAyIDE0MFE0MDYgMTQ5IDQwOSAxNTFUNDI0IDE1M1E0NDMgMTUzIDQ0MyAxNDNRNDQzIDEzOCA0NDIgMTM0UTQyNSA3MiAzNzYgMzFUMjc4IC0xMVEyNTIgLTExIDIzMiA2VDE5MyA0MFQxNTUgNTdRMTExIDU3IDc2IC0zUTcwIC0xMSA1OSAtMTFINTRINDFRMzUgLTUgMzUgLTJRMzUgMTMgOTMgODRRMTMyIDEyOSAyMjUgMjE0VDM0MCAzMjJRMzUyIDMzOCAzNDcgMzM4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY1IiBkPSJNMzkgMTY4UTM5IDIyNSA1OCAyNzJUMTA3IDM1MFQxNzQgNDAyVDI0NCA0MzNUMzA3IDQ0MkgzMTBRMzU1IDQ0MiAzODggNDIwVDQyMSAzNTVRNDIxIDI2NSAzMTAgMjM3UTI2MSAyMjQgMTc2IDIyM1ExMzkgMjIzIDEzOCAyMjFRMTM4IDIxOSAxMzIgMTg2VDEyNSAxMjhRMTI1IDgxIDE0NiA1NFQyMDkgMjZUMzAyIDQ1VDM5NCAxMTFRNDAzIDEyMSA0MDYgMTIxUTQxMCAxMjEgNDE5IDExMlQ0MjkgOThUNDIwIDgyVDM5MCA1NVQzNDQgMjRUMjgxIC0xVDIwNSAtMTFRMTI2IC0xMSA4MyA0MlQzOSAxNjhaTTM3MyAzNTNRMzY3IDQwNSAzMDUgNDA1UTI3MiA0MDUgMjQ0IDM5MVQxOTkgMzU3VDE3MCAzMTZUMTU0IDI4MFQxNDkgMjYxUTE0OSAyNjAgMTY5IDI2MFEyODIgMjYwIDMyNyAyODRUMzczIDM1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzQiIGQ9Ik00NjIgMFE0NDQgMyAzMzMgM1EyMTcgMyAxOTkgMEgxOTBWNDZIMjIxUTI0MSA0NiAyNDggNDZUMjY1IDQ4VDI3OSA1M1QyODYgNjFRMjg3IDYzIDI4NyAxMTVWMTY1SDI4VjIxMUwxNzkgNDQyUTMzMiA2NzQgMzM0IDY3NVEzMzYgNjc3IDM1NSA2NzdIMzczTDM3OSA2NzFWMjExSDQ3MVYxNjVIMzc5VjExNFEzNzkgNzMgMzc5IDY2VDM4NSA1NFEzOTMgNDcgNDQyIDQ2SDQ3MVYwSDQ2MlpNMjkzIDIxMVY1NDVMNzQgMjEyTDE4MyAyMTFIMjkzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzgiIGQ9Ik03MCA0MTdUNzAgNDk0VDEyNCA2MThUMjQ4IDY2NlEzMTkgNjY2IDM3NCA2MjRUNDI5IDUxNVE0MjkgNDg1IDQxOCA0NTlUMzkyIDQxN1QzNjEgMzg5VDMzNSAzNzFUMzI0IDM2M0wzMzggMzU0UTM1MiAzNDQgMzY2IDMzNFQzODIgMzIzUTQ1NyAyNjQgNDU3IDE3NFE0NTcgOTUgMzk5IDM3VDI0OSAtMjJRMTU5IC0yMiAxMDEgMjlUNDMgMTU1UTQzIDI2MyAxNzIgMzM1TDE1NCAzNDhRMTMzIDM2MSAxMjcgMzY4UTcwIDQxNyA3MCA0OTRaTTI4NiAzODZMMjkyIDM5MFEyOTggMzk0IDMwMSAzOTZUMzExIDQwM1QzMjMgNDEzVDMzNCA0MjVUMzQ1IDQzOFQzNTUgNDU0VDM2NCA0NzFUMzY5IDQ5MVQzNzEgNTEzUTM3MSA1NTYgMzQyIDU4NlQyNzUgNjI0UTI2OCA2MjUgMjQyIDYyNVEyMDEgNjI1IDE2NSA1OTlUMTI4IDUzNFExMjggNTExIDE0MSA0OTJUMTY3IDQ2M1QyMTcgNDMxUTIyNCA0MjYgMjI4IDQyNEwyODYgMzg2Wk0yNTAgMjFRMzA4IDIxIDM1MCA1NVQzOTIgMTM3UTM5MiAxNTQgMzg3IDE2OVQzNzUgMTk0VDM1MyAyMTZUMzMwIDIzNFQzMDEgMjUzVDI3NCAyNzBRMjYwIDI3OSAyNDQgMjg5VDIxOCAzMDZMMjEwIDMxMVEyMDQgMzExIDE4MSAyOTRUMTMzIDIzOVQxMDcgMTU3UTEwNyA5OCAxNTAgNjBUMjUwIDIxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iMTE0OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSIxNjc4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjMiIHg9IjIwNDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OCIgeD0iMjQ3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUzIiB4PSIzMDUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjM2OTUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03QSIgeD0iNDA0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY1IiB4PSI0NTA5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNDk3NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzQiIHg9IjU0MjEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSI1OTIxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjM2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM0IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjczNjciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3ODEzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzQiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODgxNCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) ,在原论文中与上图所示稍有出入,卷积结构如下:
,在原论文中与上图所示稍有出入,卷积结构如下:
- 第一层卷积核8*8,stride=4,输出通道为32,ReLU
- 第二层卷积核4*4,stride=2,输出通道为64,ReLU
- 第三层卷积核3*3,stride=1,输出通道为64,ReLU
- 第三层输出经过flat之后维度为3136,然后第四层连接一个512大小的全连接层
- 第五层为动作空间大小的输出层,Breakout游戏中为4,表示每种动作的概率

搭建CNN的py文件在q_model.py中,并手动随机生成torch.randn(32, 4, 84, 84)向量用于测试网络架构的正确性:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import cv2
import gym
import matplotlib.pyplot as plt
class QNetwork(nn.Module):
"""Actor (Policy) Model."""
def __init__(self, state_size, action_size, seed):
"""Initialize parameters and build model.
Params
======
state_size (int): Dimension of each state
action_size (int): Dimension of each action
seed (int): Random seed
"""
super(QNetwork, self).__init__()
self.seed = torch.manual_seed(seed)
"*** YOUR CODE HERE ***"
self.conv = nn.Sequential(
nn.Conv2d(state_size[1], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU()
)
self.fc = nn.Sequential(
nn.Linear(64*7*7, 512),
nn.ReLU(),
nn.Linear(512, action_size)
)
def forward(self, state):
"""Build a network that maps state -> action values."""
conv_out = self.conv(state).view(state.size()[0], -1)
return self.fc(conv_out)
def pre_process(observation):
"""Process (210, 160, 3) picture into (1, 84, 84)"""
x_t = cv2.cvtColor(cv2.resize(observation, (84, 84)), cv2.COLOR_BGR2GRAY)
ret, x_t = cv2.threshold(x_t, 1, 255, cv2.THRESH_BINARY)
return np.reshape(x_t, (1, 84, 84)), x_t
def stack_state(processed_obs):
"""Four frames as a state"""
return np.stack((processed_obs, processed_obs, processed_obs, processed_obs), axis=0)
if __name__ == '__main__':
env = gym.make('Breakout-v0')
print('State shape: ', env.observation_space.shape)
print('Number of actions: ', env.action_space.n)
obs = env.reset()
x_t, img = pre_process(obs)
state = stack_state(img)
print(np.shape(state[0]))
# plt.imshow(img, cmap='gray')
# 用cv2模块显示
# cv2.imshow('Breakout', img)
# cv2.waitKey(0)
state = torch.randn(32, 4, 84, 84) # (batch_size, color_channel, img_height,img_width)
state_size = state.size()
cnn_model = QNetwork(state_size, action_size=4, seed=1)
outputs = cnn_model(state)
print(outputs)
完成了解决维数灾难的一步,接下来我们就应该考虑训练的稳定性和效率了,这也是深度学习领域常考虑的问题。而在DQN算法中,作者提出了两大技巧来解决,就是著名的replay buffer和target network,我们一一讨论。
Replay Buffer
replay这个词很形象,在英语中用于影视剧之类的回放;buffer这个词则是计算机里的术语;两个词合起来,形象地体会一下,就是把过去的数据从一个缓存中又拿出来用,这样一用,就比较好地解决了困扰Q-learning算法的样本效率以及相关性问题。从Q-learning的原始公式和算法流程来看,每一次更新Q值的样本都只能用一次,而且在连续获取游戏画面的情景下,状态样本存在极高的相关性。针对这两个问题,如果我们使用一个较大的buffer来储存这些样本,每次随机均匀采样,既能多次使用样本,还能打破样本之间的相关性。
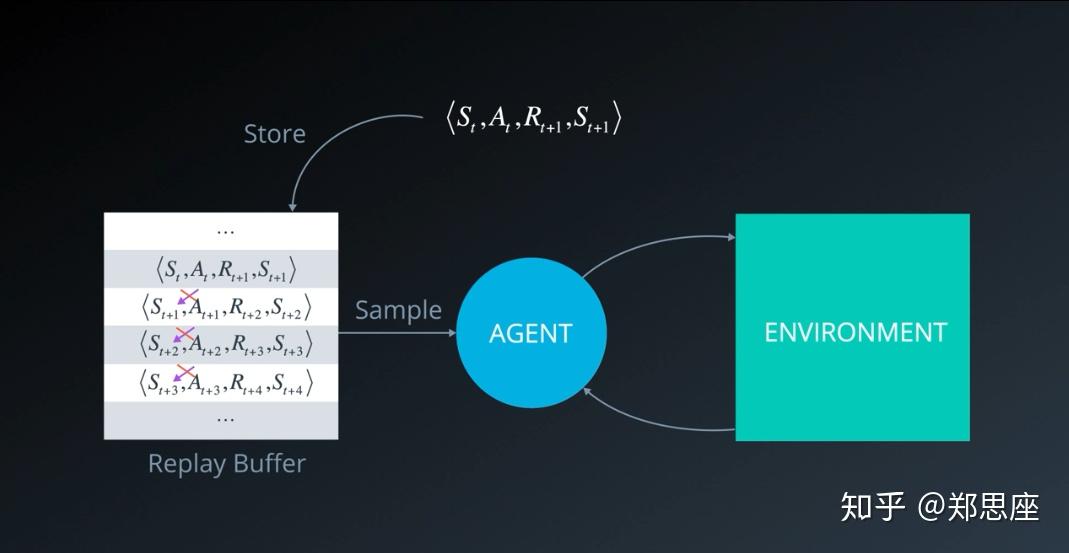
在dqn_agent.py中以ReplayBuffer来实现:
class ReplayBuffer:
"""Fixed-size buffer to store experience tuples."""
def __init__(self, action_size, buffer_size, batch_size, seed):
"""Initialize a ReplayBuffer object.
Params
======
action_size (int): dimension of each action
buffer_size (int): maximum size of buffer
batch_size (int): size of each training batch
seed (int): random seed
"""
self.action_size = action_size
self.memory = deque(maxlen=buffer_size)
self.batch_size = batch_size
self.experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "done"])
self.seed = random.seed(seed)
def add(self, state, action, reward, next_state, done):
"""Add a new experience to memory."""
e = self.experience(state, action, reward, next_state, done)
self.memory.append(e)
def sample(self):
"""Randomly sample a batch of experiences from memory."""
experiences = random.sample(self.memory, k=self.batch_size)
states = torch.from_numpy(np.stack([e.state for e in experiences if e is not None])).float().to(device)
actions = torch.from_numpy(np.vstack([e.action for e in experiences if e is not None])).long().to(device)
rewards = torch.from_numpy(np.vstack([e.reward for e in experiences if e is not None])).float().to(device)
next_states = torch.from_numpy(np.stack([e.next_state for e in experiences if e is not None])).float().to(device)
dones = torch.from_numpy(np.vstack([e.done for e in experiences if e is not None]).astype(np.uint8)).float().to(device)
return (states, actions, rewards, next_states, dones)
def __len__(self):
"""Return the current size of internal memory."""
return len(self.memory)Target Network




假设真实的动作值函数为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjguMjk3ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMzU3Mi4yIDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTM0MCA0NDEgMzcyIDM4OVEzNzMgMzkwIDM3NyAzOTVUMzg4IDQwNlQ0MDQgNDE4UTQzOCA0NDIgNDUwIDQ0MlE0NTQgNDQyIDQ1NyA0MzlUNDYwIDQzNFE0NjAgNDI1IDM5MSAxNDlRMzIwIC0xMzUgMzIwIC0xMzlRMzIwIC0xNDcgMzY1IC0xNDhIMzkwUTM5NiAtMTU2IDM5NiAtMTU3VDM5MyAtMTc1UTM4OSAtMTg4IDM4MyAtMTk0SDM3MFEzMzkgLTE5MiAyNjIgLTE5MlEyMzQgLTE5MiAyMTEgLTE5MlQxNzQgLTE5MlQxNTcgLTE5M1ExNDMgLTE5MyAxNDMgLTE4NVExNDMgLTE4MiAxNDUgLTE3MFExNDkgLTE1NCAxNTIgLTE1MVQxNzIgLTE0OFEyMjAgLTE0OCAyMzAgLTE0MVEyMzggLTEzNiAyNTggLTUzVDI3OSAzMlEyNzkgMzMgMjcyIDI5UTIyNCAtMTAgMTcyIC0xMFExMTcgLTEwIDc1IDMwVDMzIDE1N1pNMzUyIDMyNlEzMjkgNDA1IDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIzMyAyNiAyOTAgOThMMjk4IDEwOUwzNTIgMzI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTNDMCIgZD0iTTEzMiAtMTFROTggLTExIDk4IDIyVjMzTDExMSA2MVExODYgMjE5IDIyMCAzMzRMMjI4IDM1OEgxOTZRMTU4IDM1OCAxNDIgMzU1VDEwMyAzMzZROTIgMzI5IDgxIDMxOFQ2MiAyOTdUNTMgMjg1UTUxIDI4NCAzOCAyODRRMTkgMjg0IDE5IDI5NFExOSAzMDAgMzggMzI5VDkzIDM5MVQxNjQgNDI5UTE3MSA0MzEgMzg5IDQzMVE1NDkgNDMxIDU1MyA0MzBRNTczIDQyMyA1NzMgNDAyUTU3MyAzNzEgNTQxIDM2MFE1MzUgMzU4IDQ3MiAzNThINDA4TDQwNSAzNDFRMzkzIDI2OSAzOTMgMjIyUTM5MyAxNzAgNDAyIDEyOVQ0MjEgNjVUNDMxIDM3UTQzMSAyMCA0MTcgNVQzODEgLTEwUTM3MCAtMTAgMzYzIC03VDM0NyAxN1QzMzEgNzdRMzMwIDg2IDMzMCAxMjFRMzMwIDE3MCAzMzkgMjI2VDM1NyAzMThUMzY3IDM1OEgyNjlMMjY4IDM1NFEyNjggMzUxIDI0OSAyNzVUMjA2IDExNFQxNzUgMTdRMTY0IC0xMSAxMzIgLTExWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MyIgZD0iTTMwOCAyNFEzNjcgMjQgNDE2IDc2VDQ2NiAxOTdRNDY2IDI2MCA0MTQgMjg0UTMwOCAzMTEgMjc4IDMyMVQyMzYgMzQxUTE3NiAzODMgMTc2IDQ2MlExNzYgNTIzIDIwOCA1NzNUMjczIDY0OFEzMDIgNjczIDM0MyA2ODhUNDA3IDcwNEg0MThINDI1UTUyMSA3MDQgNTY0IDY0MFE1NjUgNjQwIDU3NyA2NTNUNjAzIDY4MlQ2MjMgNzA0UTYyNCA3MDQgNjI3IDcwNFQ2MzIgNzA1UTY0NSA3MDUgNjQ1IDY5OFQ2MTcgNTc3VDU4NSA0NTlUNTY5IDQ1NlE1NDkgNDU2IDU0OSA0NjVRNTQ5IDQ3MSA1NTAgNDc1UTU1MCA0NzggNTUxIDQ5NFQ1NTMgNTIwUTU1MyA1NTQgNTQ0IDU3OVQ1MjYgNjE2VDUwMSA2NDFRNDY1IDY2MiA0MTkgNjYyUTM2MiA2NjIgMzEzIDYxNlQyNjMgNTEwUTI2MyA0ODAgMjc4IDQ1OFQzMTkgNDI3UTMyMyA0MjUgMzg5IDQwOFQ0NTYgMzkwUTQ5MCAzNzkgNTIyIDM0MlQ1NTQgMjQyUTU1NCAyMTYgNTQ2IDE4NlE1NDEgMTY0IDUyOCAxMzdUNDkyIDc4VDQyNiAxOFQzMzIgLTIwUTMyMCAtMjIgMjk4IC0yMlExOTkgLTIyIDE0NCAzM0wxMzQgNDRMMTA2IDEzUTgzIC0xNCA3OCAtMThUNjUgLTIyUTUyIC0yMiA1MiAtMTRRNTIgLTExIDExMCAyMjFRMTEyIDIyNyAxMzAgMjI3SDE0M1ExNDkgMjIxIDE0OSAyMTZRMTQ5IDIxNCAxNDggMjA3VDE0NCAxODZUMTQyIDE1M1ExNDQgMTE0IDE2MCA4N1QyMDMgNDdUMjU1IDI5VDMwOCAyNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQxIiBkPSJNMjA4IDc0UTIwOCA1MCAyNTQgNDZRMjcyIDQ2IDI3MiAzNVEyNzIgMzQgMjcwIDIyUTI2NyA4IDI2NCA0VDI1MSAwUTI0OSAwIDIzOSAwVDIwNSAxVDE0MSAyUTcwIDIgNTAgMEg0MlEzNSA3IDM1IDExUTM3IDM4IDQ4IDQ2SDYyUTEzMiA0OSAxNjQgOTZRMTcwIDEwMiAzNDUgNDAxVDUyMyA3MDRRNTMwIDcxNiA1NDcgNzE2SDU1NUg1NzJRNTc4IDcwNyA1NzggNzA2TDYwNiAzODNRNjM0IDYwIDYzNiA1N1E2NDEgNDYgNzAxIDQ2UTcyNiA0NiA3MjYgMzZRNzI2IDM0IDcyMyAyMlE3MjAgNyA3MTggNFQ3MDQgMFE3MDEgMCA2OTAgMFQ2NTEgMVQ1NzggMlE0ODQgMiA0NTUgMEg0NDNRNDM3IDYgNDM3IDlUNDM5IDI3UTQ0MyA0MCA0NDUgNDNMNDQ5IDQ2SDQ2OVE1MjMgNDkgNTMzIDYzTDUyMSAyMTNIMjgzTDI0OSAxNTVRMjA4IDg2IDIwOCA3NFpNNTE2IDI2MFE1MTYgMjcxIDUwNCA0MTZUNDkwIDU2Mkw0NjMgNTE5UTQ0NyA0OTIgNDAwIDQxMkwzMTAgMjYwTDQxMyAyNTlRNTE2IDI1OSA1MTYgMjYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0MwIiB4PSI2MzEiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSI5NTIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MyIgeD0iMTM0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjE5ODciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MSIgeD0iMjQzMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODIiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,我们的训练目标是训练一个CNN使
,我们的训练目标是训练一个CNN使 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEwLjE2MWV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDQzNzQuOCAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzEiIGQ9Ik0zMyAxNTdRMzMgMjU4IDEwOSAzNDlUMjgwIDQ0MVEzNDAgNDQxIDM3MiAzODlRMzczIDM5MCAzNzcgMzk1VDM4OCA0MDZUNDA0IDQxOFE0MzggNDQyIDQ1MCA0NDJRNDU0IDQ0MiA0NTcgNDM5VDQ2MCA0MzRRNDYwIDQyNSAzOTEgMTQ5UTMyMCAtMTM1IDMyMCAtMTM5UTMyMCAtMTQ3IDM2NSAtMTQ4SDM5MFEzOTYgLTE1NiAzOTYgLTE1N1QzOTMgLTE3NVEzODkgLTE4OCAzODMgLTE5NEgzNzBRMzM5IC0xOTIgMjYyIC0xOTJRMjM0IC0xOTIgMjExIC0xOTJUMTc0IC0xOTJUMTU3IC0xOTNRMTQzIC0xOTMgMTQzIC0xODVRMTQzIC0xODIgMTQ1IC0xNzBRMTQ5IC0xNTQgMTUyIC0xNTFUMTcyIC0xNDhRMjIwIC0xNDggMjMwIC0xNDFRMjM4IC0xMzYgMjU4IC01M1QyNzkgMzJRMjc5IDMzIDI3MiAyOVEyMjQgLTEwIDE3MiAtMTBRMTE3IC0xMCA3NSAzMFQzMyAxNTdaTTM1MiAzMjZRMzI5IDQwNSAyNzcgNDA1UTI0MiA0MDUgMjEwIDM3NFQxNjAgMjkzUTEzMSAyMTQgMTE5IDEyOVExMTkgMTI2IDExOSAxMThUMTE4IDEwNlExMTggNjEgMTM2IDQ0VDE3OSAyNlEyMzMgMjYgMjkwIDk4TDI5OCAxMDlMMzUyIDMyNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTVFIiBkPSJNMTEyIDU2MEwyNDkgNjk0TDI1NyA2ODZRMzg3IDU2MiAzODcgNTYwTDM2MSA1MzFRMzU5IDUzMiAzMDMgNTgxTDI1MCA2MjdMMTk1IDU4MFExODIgNTY5IDE2OSA1NTdUMTQ4IDUzOEwxNDAgNTMyUTEzOCA1MzAgMTI1IDU0NkwxMTIgNTYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MyIgZD0iTTMwOCAyNFEzNjcgMjQgNDE2IDc2VDQ2NiAxOTdRNDY2IDI2MCA0MTQgMjg0UTMwOCAzMTEgMjc4IDMyMVQyMzYgMzQxUTE3NiAzODMgMTc2IDQ2MlExNzYgNTIzIDIwOCA1NzNUMjczIDY0OFEzMDIgNjczIDM0MyA2ODhUNDA3IDcwNEg0MThINDI1UTUyMSA3MDQgNTY0IDY0MFE1NjUgNjQwIDU3NyA2NTNUNjAzIDY4MlQ2MjMgNzA0UTYyNCA3MDQgNjI3IDcwNFQ2MzIgNzA1UTY0NSA3MDUgNjQ1IDY5OFQ2MTcgNTc3VDU4NSA0NTlUNTY5IDQ1NlE1NDkgNDU2IDU0OSA0NjVRNTQ5IDQ3MSA1NTAgNDc1UTU1MCA0NzggNTUxIDQ5NFQ1NTMgNTIwUTU1MyA1NTQgNTQ0IDU3OVQ1MjYgNjE2VDUwMSA2NDFRNDY1IDY2MiA0MTkgNjYyUTM2MiA2NjIgMzEzIDYxNlQyNjMgNTEwUTI2MyA0ODAgMjc4IDQ1OFQzMTkgNDI3UTMyMyA0MjUgMzg5IDQwOFQ0NTYgMzkwUTQ5MCAzNzkgNTIyIDM0MlQ1NTQgMjQyUTU1NCAyMTYgNTQ2IDE4NlE1NDEgMTY0IDUyOCAxMzdUNDkyIDc4VDQyNiAxOFQzMzIgLTIwUTMyMCAtMjIgMjk4IC0yMlExOTkgLTIyIDE0NCAzM0wxMzQgNDRMMTA2IDEzUTgzIC0xNCA3OCAtMThUNjUgLTIyUTUyIC0yMiA1MiAtMTRRNTIgLTExIDExMCAyMjFRMTEyIDIyNyAxMzAgMjI3SDE0M1ExNDkgMjIxIDE0OSAyMTZRMTQ5IDIxNCAxNDggMjA3VDE0NCAxODZUMTQyIDE1M1ExNDQgMTE0IDE2MCA4N1QyMDMgNDdUMjU1IDI5VDMwOCAyNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQxIiBkPSJNMjA4IDc0UTIwOCA1MCAyNTQgNDZRMjcyIDQ2IDI3MiAzNVEyNzIgMzQgMjcwIDIyUTI2NyA4IDI2NCA0VDI1MSAwUTI0OSAwIDIzOSAwVDIwNSAxVDE0MSAyUTcwIDIgNTAgMEg0MlEzNSA3IDM1IDExUTM3IDM4IDQ4IDQ2SDYyUTEzMiA0OSAxNjQgOTZRMTcwIDEwMiAzNDUgNDAxVDUyMyA3MDRRNTMwIDcxNiA1NDcgNzE2SDU1NUg1NzJRNTc4IDcwNyA1NzggNzA2TDYwNiAzODNRNjM0IDYwIDYzNiA1N1E2NDEgNDYgNzAxIDQ2UTcyNiA0NiA3MjYgMzZRNzI2IDM0IDcyMyAyMlE3MjAgNyA3MTggNFQ3MDQgMFE3MDEgMCA2OTAgMFQ2NTEgMVQ1NzggMlE0ODQgMiA0NTUgMEg0NDNRNDM3IDYgNDM3IDlUNDM5IDI3UTQ0MyA0MCA0NDUgNDNMNDQ5IDQ2SDQ2OVE1MjMgNDkgNTMzIDYzTDUyMSAyMTNIMjgzTDI0OSAxNTVRMjA4IDg2IDIwOCA3NFpNNTE2IDI2MFE1MTYgMjcxIDUwNCA0MTZUNDkwIDU2Mkw0NjMgNTE5UTQ0NyA0OTIgNDAwIDQxMkwzMTAgMjYwTDQxMyAyNTlRNTE2IDI1OSA1MTYgMjYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc3IiBkPSJNNTgwIDM4NVE1ODAgNDA2IDU5OSA0MjRUNjQxIDQ0M1E2NTkgNDQzIDY3NCA0MjVUNjkwIDM2OFE2OTAgMzM5IDY3MSAyNTNRNjU2IDE5NyA2NDQgMTYxVDYwOSA4MFQ1NTQgMTJUNDgyIC0xMVE0MzggLTExIDQwNCA1VDM1NSA0OFEzNTQgNDcgMzUyIDQ0UTMxMSAtMTEgMjUyIC0xMVEyMjYgLTExIDIwMiAtNVQxNTUgMTRUMTE4IDUzVDEwNCAxMTZRMTA0IDE3MCAxMzggMjYyVDE3MyAzNzlRMTczIDM4MCAxNzMgMzgxUTE3MyAzOTAgMTczIDM5M1QxNjkgNDAwVDE1OCA0MDRIMTU0UTEzMSA0MDQgMTEyIDM4NVQ4MiAzNDRUNjUgMzAyVDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdRMjEgMjkzIDI5IDMxNVQ1MiAzNjZUOTYgNDE4VDE2MSA0NDFRMjA0IDQ0MSAyMjcgNDE2VDI1MCAzNThRMjUwIDM0MCAyMTcgMjUwVDE4NCAxMTFRMTg0IDY1IDIwNSA0NlQyNTggMjZRMzAxIDI2IDMzNCA4N0wzMzkgOTZWMTE5UTMzOSAxMjIgMzM5IDEyOFQzNDAgMTM2VDM0MSAxNDNUMzQyIDE1MlQzNDUgMTY1VDM0OCAxODJUMzU0IDIwNlQzNjIgMjM4VDM3MyAyODFRNDAyIDM5NSA0MDYgNDA0UTQxOSA0MzEgNDQ5IDQzMVE0NjggNDMxIDQ3NSA0MjFUNDgzIDQwMlE0ODMgMzg5IDQ1NCAyNzRUNDIyIDE0MlE0MjAgMTMxIDQyMCAxMDdWMTAwUTQyMCA4NSA0MjMgNzFUNDQyIDQyVDQ4NyAyNlE1NTggMjYgNjAwIDE0OFE2MDkgMTcxIDYyMCAyMTNUNjMyIDI3M1E2MzIgMzA2IDYxOSAzMjVUNTkzIDM1N1Q1ODAgMzg1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzEiIHg9IjIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01RSIgeD0iOTIiIHk9IjIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iNTkyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTMiIHg9Ijk4MiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjE2MjciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MSIgeD0iMjA3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjI4MjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NyIgeD0iMzI2OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM5ODUiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 能够逼近它,经过对梯度的求导,感觉上我们希望TD目标值
能够逼近它,经过对梯度的求导,感觉上我们希望TD目标值 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI0LjA1NGV4IiBoZWlnaHQ9IjQuMDA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4wMDVleDsiIHZpZXdCb3g9IjAgLTg2My4xIDEwMzU2LjUgMTcyNi4yIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTNCMyIgZD0iTTMxIDI0OVExMSAyNDkgMTEgMjU4UTExIDI3NSAyNiAzMDRUNjYgMzY1VDEyOSA0MThUMjA2IDQ0MVEyMzMgNDQxIDIzOSA0NDBRMjg3IDQyOSAzMTggMzg2VDM3MSAyNTVRMzg1IDE5NSAzODUgMTcwUTM4NSAxNjYgMzg2IDE2NkwzOTggMTkzUTQxOCAyNDQgNDQzIDMwMFQ0ODYgMzkxVDUwOCA0MzBRNTEwIDQzMSA1MjQgNDMxSDUzN1E1NDMgNDI1IDU0MyA0MjJRNTQzIDQxOCA1MjIgMzc4VDQ2MyAyNTFUMzkxIDcxUTM4NSA1NSAzNzggNlQzNTcgLTEwMFEzNDEgLTE2NSAzMzAgLTE5MFQzMDMgLTIxNlEyODYgLTIxNiAyODYgLTE4OFEyODYgLTEzOCAzNDAgMzJMMzQ2IDUxTDM0NyA2OVEzNDggNzkgMzQ4IDEwMFEzNDggMjU3IDI5MSAzMTdRMjUxIDM1NSAxOTYgMzU1UTE0OCAzNTUgMTA4IDMyOVQ1MSAyNjBRNDkgMjUxIDQ3IDI1MVE0NSAyNDkgMzEgMjQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNkQiIGQ9Ik00MSA0Nkg1NVE5NCA0NiAxMDIgNjBWNjhRMTAyIDc3IDEwMiA5MVQxMDIgMTIyVDEwMyAxNjFUMTAzIDIwM1ExMDMgMjM0IDEwMyAyNjlUMTAyIDMyOFYzNTFROTkgMzcwIDg4IDM3NlQ0MyAzODVIMjVWNDA4UTI1IDQzMSAyNyA0MzFMMzcgNDMyUTQ3IDQzMyA2NSA0MzRUMTAyIDQzNlExMTkgNDM3IDEzOCA0MzhUMTY3IDQ0MVQxNzggNDQySDE4MVY0MDJRMTgxIDM2NCAxODIgMzY0VDE4NyAzNjlUMTk5IDM4NFQyMTggNDAyVDI0NyA0MjFUMjg1IDQzN1EzMDUgNDQyIDMzNiA0NDJRMzUxIDQ0MiAzNjQgNDQwVDM4NyA0MzRUNDA2IDQyNlQ0MjEgNDE3VDQzMiA0MDZUNDQxIDM5NVQ0NDggMzg0VDQ1MiAzNzRUNDU1IDM2Nkw0NTcgMzYxTDQ2MCAzNjVRNDYzIDM2OSA0NjYgMzczVDQ3NSAzODRUNDg4IDM5N1Q1MDMgNDEwVDUyMyA0MjJUNTQ2IDQzMlQ1NzIgNDM5VDYwMyA0NDJRNzI5IDQ0MiA3NDAgMzI5UTc0MSAzMjIgNzQxIDE5MFYxMDRRNzQxIDY2IDc0MyA1OVQ3NTQgNDlRNzc1IDQ2IDgwMyA0Nkg4MTlWMEg4MTFMNzg4IDFRNzY0IDIgNzM3IDJUNjk5IDNRNTk2IDMgNTg3IDBINTc5VjQ2SDU5NVE2NTYgNDYgNjU2IDYyUTY1NyA2NCA2NTcgMjAwUTY1NiAzMzUgNjU1IDM0M1E2NDkgMzcxIDYzNSAzODVUNjExIDQwMlQ1ODUgNDA0UTU0MCA0MDQgNTA2IDM3MFE0NzkgMzQzIDQ3MiAzMTVUNDY0IDIzMlYxNjhWMTA4UTQ2NCA3OCA0NjUgNjhUNDY4IDU1VDQ3NyA0OVE0OTggNDYgNTI2IDQ2SDU0MlYwSDUzNEw1MTAgMVE0ODcgMiA0NjAgMlQ0MjIgM1EzMTkgMyAzMTAgMEgzMDJWNDZIMzE4UTM3OSA0NiAzNzkgNjJRMzgwIDY0IDM4MCAyMDBRMzc5IDMzNSAzNzggMzQzUTM3MiAzNzEgMzU4IDM4NVQzMzQgNDAyVDMwOCA0MDRRMjYzIDQwNCAyMjkgMzcwUTIwMiAzNDMgMTk1IDMxNVQxODcgMjMyVjE2OFYxMDhRMTg3IDc4IDE4OCA2OFQxOTEgNTVUMjAwIDQ5UTIyMSA0NiAyNDkgNDZIMjY1VjBIMjU3TDIzNCAxUTIxMCAyIDE4MyAyVDE0NSAzUTQyIDMgMzMgMEgyNVY0Nkg0MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzgiIGQ9Ik0yMDEgMFExODkgMyAxMDIgM1EyNiAzIDE3IDBIMTFWNDZIMjVRNDggNDcgNjcgNTJUOTYgNjFUMTIxIDc4VDEzOSA5NlQxNjAgMTIyVDE4MCAxNTBMMjI2IDIxMEwxNjggMjg4UTE1OSAzMDEgMTQ5IDMxNVQxMzMgMzM2VDEyMiAzNTFUMTEzIDM2M1QxMDcgMzcwVDEwMCAzNzZUOTQgMzc5VDg4IDM4MVQ4MCAzODNRNzQgMzgzIDQ0IDM4NUgxNlY0MzFIMjNRNTkgNDI5IDEyNiA0MjlRMjE5IDQyOSAyMjkgNDMxSDIzN1YzODVRMjAxIDM4MSAyMDEgMzY5UTIwMSAzNjcgMjExIDM1M1QyMzkgMzE1VDI2OCAyNzRMMjcyIDI3MEwyOTcgMzA0UTMyOSAzNDUgMzI5IDM1OFEzMjkgMzY0IDMyNyAzNjlUMzIyIDM3NlQzMTcgMzgwVDMxMCAzODRMMzA3IDM4NUgzMDJWNDMxSDMwOVEzMjQgNDI4IDQwOCA0MjhRNDg3IDQyOCA0OTMgNDMxSDQ5OVYzODVINDkyUTQ0MyAzODUgNDExIDM2OFEzOTQgMzYwIDM3NyAzNDFUMzEyIDI1N0wyOTYgMjM2TDM1OCAxNTFRNDI0IDYxIDQyOSA1N1Q0NDYgNTBRNDY0IDQ2IDQ5OSA0Nkg1MTZWMEg1MTBINTAyUTQ5NCAxIDQ4MiAxVDQ1NyAyVDQzMiAyVDQxNCAzUTQwMyAzIDM3NyAzVDMyNyAxTDMwNCAwSDI5NVY0NkgyOThRMzA5IDQ2IDMyMCA1MVQzMzEgNjNRMzMxIDY1IDI5MSAxMjBMMjUwIDE3NVEyNDkgMTc0IDIxOSAxMzNUMTg1IDg4UTE4MSA4MyAxODEgNzRRMTgxIDYzIDE4OCA1NVQyMDYgNDZRMjA4IDQ2IDIwOCAyM1YwSDIwMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTM0MCA0NDEgMzcyIDM4OVEzNzMgMzkwIDM3NyAzOTVUMzg4IDQwNlQ0MDQgNDE4UTQzOCA0NDIgNDUwIDQ0MlE0NTQgNDQyIDQ1NyA0MzlUNDYwIDQzNFE0NjAgNDI1IDM5MSAxNDlRMzIwIC0xMzUgMzIwIC0xMzlRMzIwIC0xNDcgMzY1IC0xNDhIMzkwUTM5NiAtMTU2IDM5NiAtMTU3VDM5MyAtMTc1UTM4OSAtMTg4IDM4MyAtMTk0SDM3MFEzMzkgLTE5MiAyNjIgLTE5MlEyMzQgLTE5MiAyMTEgLTE5MlQxNzQgLTE5MlQxNTcgLTE5M1ExNDMgLTE5MyAxNDMgLTE4NVExNDMgLTE4MiAxNDUgLTE3MFExNDkgLTE1NCAxNTIgLTE1MVQxNzIgLTE0OFEyMjAgLTE0OCAyMzAgLTE0MVEyMzggLTEzNiAyNTggLTUzVDI3OSAzMlEyNzkgMzMgMjcyIDI5UTIyNCAtMTAgMTcyIC0xMFExMTcgLTEwIDc1IDMwVDMzIDE1N1pNMzUyIDMyNlEzMjkgNDA1IDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIzMyAyNiAyOTAgOThMMjk4IDEwOUwzNTIgMzI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUUiIGQ9Ik0xMTIgNTYwTDI0OSA2OTRMMjU3IDY4NlEzODcgNTYyIDM4NyA1NjBMMzYxIDUzMVEzNTkgNTMyIDMwMyA1ODFMMjUwIDYyN0wxOTUgNTgwUTE4MiA1NjkgMTY5IDU1N1QxNDggNTM4TDE0MCA1MzJRMTM4IDUzMCAxMjUgNTQ2TDExMiA1NjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUzIiBkPSJNMzA4IDI0UTM2NyAyNCA0MTYgNzZUNDY2IDE5N1E0NjYgMjYwIDQxNCAyODRRMzA4IDMxMSAyNzggMzIxVDIzNiAzNDFRMTc2IDM4MyAxNzYgNDYyUTE3NiA1MjMgMjA4IDU3M1QyNzMgNjQ4UTMwMiA2NzMgMzQzIDY4OFQ0MDcgNzA0SDQxOEg0MjVRNTIxIDcwNCA1NjQgNjQwUTU2NSA2NDAgNTc3IDY1M1Q2MDMgNjgyVDYyMyA3MDRRNjI0IDcwNCA2MjcgNzA0VDYzMiA3MDVRNjQ1IDcwNSA2NDUgNjk4VDYxNyA1NzdUNTg1IDQ1OVQ1NjkgNDU2UTU0OSA0NTYgNTQ5IDQ2NVE1NDkgNDcxIDU1MCA0NzVRNTUwIDQ3OCA1NTEgNDk0VDU1MyA1MjBRNTUzIDU1NCA1NDQgNTc5VDUyNiA2MTZUNTAxIDY0MVE0NjUgNjYyIDQxOSA2NjJRMzYyIDY2MiAzMTMgNjE2VDI2MyA1MTBRMjYzIDQ4MCAyNzggNDU4VDMxOSA0MjdRMzIzIDQyNSAzODkgNDA4VDQ1NiAzOTBRNDkwIDM3OSA1MjIgMzQyVDU1NCAyNDJRNTU0IDIxNiA1NDYgMTg2UTU0MSAxNjQgNTI4IDEzN1Q0OTIgNzhUNDI2IDE4VDMzMiAtMjBRMzIwIC0yMiAyOTggLTIyUTE5OSAtMjIgMTQ0IDMzTDEzNCA0NEwxMDYgMTNRODMgLTE0IDc4IC0xOFQ2NSAtMjJRNTIgLTIyIDUyIC0xNFE1MiAtMTEgMTEwIDIyMVExMTIgMjI3IDEzMCAyMjdIMTQzUTE0OSAyMjEgMTQ5IDIxNlExNDkgMjE0IDE0OCAyMDdUMTQ0IDE4NlQxNDIgMTUzUTE0NCAxMTQgMTYwIDg3VDIwMyA0N1QyNTUgMjlUMzA4IDI0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkMiIGQ9Ik03OCAzNVQ3OCA2MFQ5NCAxMDNUMTM3IDEyMVExNjUgMTIxIDE4NyA5NlQyMTAgOFEyMTAgLTI3IDIwMSAtNjBUMTgwIC0xMTdUMTU0IC0xNThUMTMwIC0xODVUMTE3IC0xOTRRMTEzIC0xOTQgMTA0IC0xODVUOTUgLTE3MlE5NSAtMTY4IDEwNiAtMTU2VDEzMSAtMTI2VDE1NyAtNzZUMTczIC0zVjlMMTcyIDhRMTcwIDcgMTY3IDZUMTYxIDNUMTUyIDFUMTQwIDBRMTEzIDAgOTYgMTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDEiIGQ9Ik0yMDggNzRRMjA4IDUwIDI1NCA0NlEyNzIgNDYgMjcyIDM1UTI3MiAzNCAyNzAgMjJRMjY3IDggMjY0IDRUMjUxIDBRMjQ5IDAgMjM5IDBUMjA1IDFUMTQxIDJRNzAgMiA1MCAwSDQyUTM1IDcgMzUgMTFRMzcgMzggNDggNDZINjJRMTMyIDQ5IDE2NCA5NlExNzAgMTAyIDM0NSA0MDFUNTIzIDcwNFE1MzAgNzE2IDU0NyA3MTZINTU1SDU3MlE1NzggNzA3IDU3OCA3MDZMNjA2IDM4M1E2MzQgNjAgNjM2IDU3UTY0MSA0NiA3MDEgNDZRNzI2IDQ2IDcyNiAzNlE3MjYgMzQgNzIzIDIyUTcyMCA3IDcxOCA0VDcwNCAwUTcwMSAwIDY5MCAwVDY1MSAxVDU3OCAyUTQ4NCAyIDQ1NSAwSDQ0M1E0MzcgNiA0MzcgOVQ0MzkgMjdRNDQzIDQwIDQ0NSA0M0w0NDkgNDZINDY5UTUyMyA0OSA1MzMgNjNMNTIxIDIxM0gyODNMMjQ5IDE1NVEyMDggODYgMjA4IDc0Wk01MTYgMjYwUTUxNiAyNzEgNTA0IDQxNlQ0OTAgNTYyTDQ2MyA1MTlRNDQ3IDQ5MiA0MDAgNDEyTDMxMCAyNjBMNDEzIDI1OVE1MTYgMjU5IDUxNiAyNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzciIGQ9Ik01ODAgMzg1UTU4MCA0MDYgNTk5IDQyNFQ2NDEgNDQzUTY1OSA0NDMgNjc0IDQyNVQ2OTAgMzY4UTY5MCAzMzkgNjcxIDI1M1E2NTYgMTk3IDY0NCAxNjFUNjA5IDgwVDU1NCAxMlQ0ODIgLTExUTQzOCAtMTEgNDA0IDVUMzU1IDQ4UTM1NCA0NyAzNTIgNDRRMzExIC0xMSAyNTIgLTExUTIyNiAtMTEgMjAyIC01VDE1NSAxNFQxMTggNTNUMTA0IDExNlExMDQgMTcwIDEzOCAyNjJUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1EyMSAyOTMgMjkgMzE1VDUyIDM2NlQ5NiA0MThUMTYxIDQ0MVEyMDQgNDQxIDIyNyA0MTZUMjUwIDM1OFEyNTAgMzQwIDIxNyAyNTBUMTg0IDExMVExODQgNjUgMjA1IDQ2VDI1OCAyNlEzMDEgMjYgMzM0IDg3TDMzOSA5NlYxMTlRMzM5IDEyMiAzMzkgMTI4VDM0MCAxMzZUMzQxIDE0M1QzNDIgMTUyVDM0NSAxNjVUMzQ4IDE4MlQzNTQgMjA2VDM2MiAyMzhUMzczIDI4MVE0MDIgMzk1IDQwNiA0MDRRNDE5IDQzMSA0NDkgNDMxUTQ2OCA0MzEgNDc1IDQyMVQ0ODMgNDAyUTQ4MyAzODkgNDU0IDI3NFQ0MjIgMTQyUTQyMCAxMzEgNDIwIDEwN1YxMDBRNDIwIDg1IDQyMyA3MVQ0NDIgNDJUNDg3IDI2UTU1OCAyNiA2MDAgMTQ4UTYwOSAxNzEgNjIwIDIxM1Q2MzIgMjczUTYzMiAzMDYgNjE5IDMyNVQ1OTMgMzU3VDU4MCAzODVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1OSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIzNjEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTE0MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjI0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCMyIgeD0iMzI0MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZEIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iODMzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03OCIgeD0iMTMzNCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iMTA1MiIgeT0iLTg2NiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTk4MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcxIiB4PSIyMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNUUiIHg9IjkyIiB5PSIyMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iNjU3NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUzIiB4PSI2OTY0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNzYwOSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQxIiB4PSI4MDU0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iODgwNSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc3IiB4PSI5MjUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iOTk2NyIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 与 应该是一回事,但实际上由于 是不依赖于参数w的,而TD目标值依赖于参数w,这在数学上是不合理的。也就是说TD目标值本来就是估计值,与旧的估计值作差再去更新
与 应该是一回事,但实际上由于 是不依赖于参数w的,而TD目标值依赖于参数w,这在数学上是不合理的。也就是说TD目标值本来就是估计值,与旧的估计值作差再去更新 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuNmV4IiBoZWlnaHQ9IjIuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC4zMzhleDsiIHZpZXdCb3g9IjAgLTc5MS4zIDE1NTAgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zOTQiIGQ9Ik01MSAwUTQ2IDQgNDYgN1E0NiA5IDIxNSAzNTdUMzg4IDcwOVEzOTEgNzE2IDQxNiA3MTZRNDM5IDcxNiA0NDQgNzA5UTQ0NyA3MDUgNjE2IDM1N1Q3ODYgN1E3ODYgNCA3ODEgMEg1MVpNNTA3IDM0NEwzODQgNTk2TDEzNyA5MkwzODMgOTFINjMwUTYzMCA5MyA1MDcgMzQ0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc3IiBkPSJNNTgwIDM4NVE1ODAgNDA2IDU5OSA0MjRUNjQxIDQ0M1E2NTkgNDQzIDY3NCA0MjVUNjkwIDM2OFE2OTAgMzM5IDY3MSAyNTNRNjU2IDE5NyA2NDQgMTYxVDYwOSA4MFQ1NTQgMTJUNDgyIC0xMVE0MzggLTExIDQwNCA1VDM1NSA0OFEzNTQgNDcgMzUyIDQ0UTMxMSAtMTEgMjUyIC0xMVEyMjYgLTExIDIwMiAtNVQxNTUgMTRUMTE4IDUzVDEwNCAxMTZRMTA0IDE3MCAxMzggMjYyVDE3MyAzNzlRMTczIDM4MCAxNzMgMzgxUTE3MyAzOTAgMTczIDM5M1QxNjkgNDAwVDE1OCA0MDRIMTU0UTEzMSA0MDQgMTEyIDM4NVQ4MiAzNDRUNjUgMzAyVDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdRMjEgMjkzIDI5IDMxNVQ1MiAzNjZUOTYgNDE4VDE2MSA0NDFRMjA0IDQ0MSAyMjcgNDE2VDI1MCAzNThRMjUwIDM0MCAyMTcgMjUwVDE4NCAxMTFRMTg0IDY1IDIwNSA0NlQyNTggMjZRMzAxIDI2IDMzNCA4N0wzMzkgOTZWMTE5UTMzOSAxMjIgMzM5IDEyOFQzNDAgMTM2VDM0MSAxNDNUMzQyIDE1MlQzNDUgMTY1VDM0OCAxODJUMzU0IDIwNlQzNjIgMjM4VDM3MyAyODFRNDAyIDM5NSA0MDYgNDA0UTQxOSA0MzEgNDQ5IDQzMVE0NjggNDMxIDQ3NSA0MjFUNDgzIDQwMlE0ODMgMzg5IDQ1NCAyNzRUNDIyIDE0MlE0MjAgMTMxIDQyMCAxMDdWMTAwUTQyMCA4NSA0MjMgNzFUNDQyIDQyVDQ4NyAyNlE1NTggMjYgNjAwIDE0OFE2MDkgMTcxIDYyMCAyMTNUNjMyIDI3M1E2MzIgMzA2IDYxOSAzMjVUNTkzIDM1N1Q1ODAgMzg1WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzk0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzciIHg9IjgzMyIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) ,就感觉像追着一个移动的目标却一直够不着。论文作者提出设置一个target network,而之前与环境交互产生动作的网络称为behavior network,训练开始时二者使用一样的架构和参数,训练过程中每完成一定数目的迭代,behavior network的参数就同步给target network。这是原始论文中提出更新方法,而在笔者的代码中,借鉴了DDPG中soft update法。
,就感觉像追着一个移动的目标却一直够不着。论文作者提出设置一个target network,而之前与环境交互产生动作的网络称为behavior network,训练开始时二者使用一样的架构和参数,训练过程中每完成一定数目的迭代,behavior network的参数就同步给target network。这是原始论文中提出更新方法,而在笔者的代码中,借鉴了DDPG中soft update法。
import numpy as np
import random
from collections import namedtuple, deque
from q_model import QNetwork
import torch
import torch.nn.functional as F
import torch.optim as optim
BUFFER_SIZE = int(1e6) # replay buffer size
BATCH_SIZE = 32 # minibatch size
GAMMA = 0.99 # discount factor
TAU = 1e-3 # for soft update of target parameters
LR = 1e-5 # learning rate
UPDATE_EVERY = 4 # how often to update the network
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
class Agent():
"""Interacts with and learns from the environment."""
def __init__(self, state_size, action_size, seed):
"""Initialize an Agent object.
Params
======
state_size (int): dimension of each state
action_size (int): dimension of each action
seed (int): random seed
"""
self.state_size = state_size
self.action_size = action_size
self.seed = random.seed(seed)
# Q-Network
self.qnetwork_local = QNetwork(state_size, action_size, seed).to(device) # behavior network
self.qnetwork_target = QNetwork(state_size, action_size, seed).to(device) # target network
self.optimizer = optim.Adam(self.qnetwork_local.parameters(), lr=LR)
# Replay memory
self.memory = ReplayBuffer(action_size, BUFFER_SIZE, BATCH_SIZE, seed)
# Initialize time step (for updating every UPDATE_EVERY steps)
self.t_step = 0
def step(self, state, action, reward, next_state, done):
# Save experience in replay memory
self.memory.add(state, action, reward, next_state, done)
# Learn every UPDATE_EVERY time steps.
self.t_step = (self.t_step + 1) % UPDATE_EVERY
if self.t_step == 0:
# If enough samples are available in memory, get random subset and learn
if len(self.memory) > BATCH_SIZE:
experiences = self.memory.sample()
self.learn(experiences, GAMMA)
def act(self, state, eps=0.):
"""Returns actions for given state as per current policy.
Params
======
state (array_like): current state
eps (float): epsilon, for epsilon-greedy action selection
"""
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
self.qnetwork_local.eval()
with torch.no_grad():
action_values = self.qnetwork_local(state)
self.qnetwork_local.train()
# Epsilon-greedy action selection
if random.random() > eps:
return np.argmax(action_values.cpu().data.numpy())
else:
return random.choice(np.arange(self.action_size))
def learn(self, experiences, gamma):
"""Update value parameters using given batch of experience tuples.
Params
======
experiences (Tuple[torch.Tensor]): tuple of (s, a, r, s', done) tuples
gamma (float): discount factor
"""
states, actions, rewards, next_states, dones = experiences
## TODO: compute and minimize the loss
# Get max predicted Q values (for next states) from target model
Q_targets_next = self.qnetwork_target(next_states).detach().max(1)[0].unsqueeze(1)
# Compute Q targets for current states
Q_targets = rewards + (gamma * Q_targets_next * (1 - dones))
Q_expected = self.qnetwork_local(states).gather(1, actions) # 固定行号,确认列号
# Compute loss
loss = F.mse_loss(Q_expected, Q_targets)
# Minimize the loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# ------------------- update target network ------------------- #
self.soft_update(self.qnetwork_local, self.qnetwork_target, TAU)
def soft_update(self, local_model, target_model, tau):
"""Soft update model parameters.
θ_target = τ*θ_local + (1 - τ)*θ_target
Params
======
local_model (PyTorch model): weights will be copied from
target_model (PyTorch model): weights will be copied to
tau (float): interpolation parameter
"""
for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):
target_param.data.copy_(tau*local_param.data + (1.0-tau)*target_param.data)DQN算法流程


我们以打砖块游戏Breakout来测试整套算法流程,整个流程的代码在Deep_Q_network.py中,超参数设置在dqn_agent.py中,其中最为重要的超参数设置是replay buffer的大小、迭代次数、学习率和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuOTQ0ZXgiIGhlaWdodD0iMS42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNTc2LjEgNDA2LjUgNzIxLjYiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0Y1IiBkPSJNMjI3IC0xMVExNDkgLTExIDk1IDQxVDQwIDE3NFE0MCAyNjIgODcgMzIyUTEyMSAzNjcgMTczIDM5NlQyODcgNDMwUTI4OSA0MzEgMzI5IDQzMUgzNjdRMzgyIDQyNiAzODIgNDExUTM4MiAzODUgMzQxIDM4NUgzMjVIMzEyUTE5MSAzODUgMTU0IDI3N0wxNTAgMjY1SDMyN1EzNDAgMjU2IDM0MCAyNDZRMzQwIDIyOCAzMjAgMjE5SDEzOFYyMTdRMTI4IDE4NyAxMjggMTQzUTEyOCA3NyAxNjAgNTJUMjMxIDI2UTI1OCAyNiAyODQgMzZUMzI2IDU3VDM0MyA2OFEzNTAgNjggMzU0IDU4VDM1OCAzOVEzNTggMzYgMzU3IDM1UTM1NCAzMSAzMzcgMjFUMjg5IDBUMjI3IC0xMVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zRjUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 衰减率。replay buffer大小至少设置为100万,迭代次数也是越多越好。
衰减率。replay buffer大小至少设置为100万,迭代次数也是越多越好。
import gym
import random
import torch
import numpy as np
from collections import deque
from dqn_agent import Agent
import matplotlib.pyplot as plt
import cv2
import time
env = gym.make('Breakout-v0')
state_size = env.observation_space.shape
action_size = env.action_space.n
print('Original state shape: ', state_size)
print('Number of actions: ', env.action_space.n)
agent = Agent((32, 4, 84, 84), action_size, seed=1) # state size (batch_size, 4 frames, img_height, img_width)
TRAIN = False # train or test flag
def pre_process(observation):
"""Process (210, 160, 3) picture into (1, 84, 84)"""
x_t = cv2.cvtColor(cv2.resize(observation, (84, 84)), cv2.COLOR_BGR2GRAY)
ret, x_t = cv2.threshold(x_t, 1, 255, cv2.THRESH_BINARY)
return x_t
def init_state(processed_obs):
return np.stack((processed_obs, processed_obs, processed_obs, processed_obs), axis=0)
def dqn(n_episodes=30000, max_t=40000, eps_start=1.0, eps_end=0.01, eps_decay=0.9995):
"""Deep Q-Learning.
Params
======
n_episodes (int): maximum number of training episodes
max_t (int): maximum number of timesteps per episode, maximum frames
eps_start (float): starting value of epsilon, for epsilon-greedy action selection
eps_end (float): minimum value of epsilon
eps_decay (float): multiplicative factor (per episode) for decreasing epsilon
"""
scores = [] # list containing scores from each episode
scores_window = deque(maxlen=100) # last 100 scores
eps = eps_start # initialize epsilon
for i_episode in range(1, n_episodes + 1):
obs = env.reset()
obs = pre_process(obs)
state = init_state(obs)
score = 0
for t in range(max_t):
action = agent.act(state, eps)
next_state, reward, done, _ = env.step(action)
# last three frames and current frame as the next state
next_state = np.stack((state[1], state[2], state[3], pre_process(next_state)), axis=0)
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
if done:
break
scores_window.append(score) # save most recent score
scores.append(score) # save most recent score
eps = max(eps_end, eps_decay * eps) # decrease epsilon
print('\tEpsilon now : {:.2f}'.format(eps))
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_window)), end="")
if i_episode % 1000 == 0:
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_window)))
print('\rEpisode {}\tThe length of replay buffer now: {}'.format(i_episode, len(agent.memory)))
if np.mean(scores_window) >= 50.0:
print('\nEnvironment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(i_episode - 100,
np.mean(scores_window)))
torch.save(agent.qnetwork_local.state_dict(), 'checkpoint/dqn_checkpoint_solved.pth')
break
torch.save(agent.qnetwork_local.state_dict(), 'checkpoint/dqn_checkpoint_8.pth')
return scores
if __name__ == '__main__':
if TRAIN:
start_time = time.time()
scores = dqn()
print('COST: {} min'.format((time.time() - start_time)/60))
print("Max score:", np.max(scores))
# plot the scores
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
else:
# load the weights from file
agent.qnetwork_local.load_state_dict(torch.load('checkpoint/dqn_checkpoint_8.pth'))
rewards = []
for i in range(10): # episodes, play ten times
total_reward = 0
obs = env.reset()
obs = pre_process(obs)
state = init_state(obs)
for j in range(10000): # frames, in case stuck in one frame
action = agent.act(state)
env.render()
next_state, reward, done, _ = env.step(action)
state = np.stack((state[1], state[2], state[3], pre_process(next_state)), axis=0)
total_reward += reward
# time.sleep(0.01)
if done:
rewards.append(total_reward)
break
print("Test rewards are:", *rewards)
print("Average reward:", np.mean(rewards))
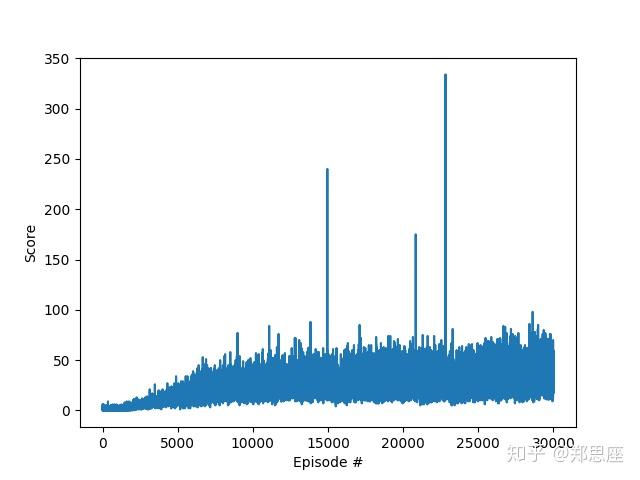
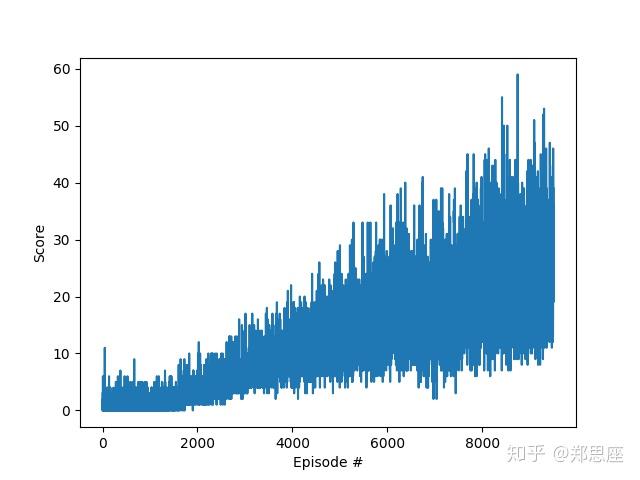
env.close()在Titan XP显卡运行,分布经过1万次和3万次迭代,统计回报曲线如下两幅图。据图中分析可知,回报曲线波动性较大,但整体趋势是在上升;在三万次游戏中,最高的一次接近350,但这一次结果十分良好的训练并不会对后面造成过多影响,这也是DQN饱受困扰的“灾难性遗忘”问题(catastrophic forgetting)。

最后的最后,上效果视频和GitHub仓库(代码是基于Udacity课程代码改的)!


11 条评论
求问,视频是怎么从gym里面导出的呀
请问这4种动作代表什么意思呢?向左,向右还有什么?
我出来的训练效果比题主差一点 但是也差不多有30分的平均分 最高分差不多40多分 运气好的话能达到80-100分左右 但是相比于其他算法还有相当大的差距 比如A3C 在仅仅三个小时之内就能达到800分左右 楼主知道是为啥吗 为啥差距会这么大
还有一件事想问题主 我看某些博客或者paper上说他们能用DQN玩到几百分以上 但是我的30-40分左右就收敛了并且就开始剧烈的震荡 我想问下这又是啥原因呀
我想问作者两个问题,这两个问题在困扰我:
1、在NatureDQN论文中,Breakout的表现是401.2分,这似乎与您训练出来的得分相差甚远,我也没有复现出接近的得分,请问您知道是什么原因吗?
2、在原文中训练次数的标注是Epoch,这与强化学习中经常说的Episode有什么区别和联系?